Date: Wed, 14 Nov 2007 03:04:16 +0200
Hi Adrian and all,
Sorry it's taken me so long to get back but I wanted to be sure I had all
my ducks in a row. I couldn't find a program to graph what we needed, so I
wrote a small script to log results - I've now done multiple tests, with
multiple disk types etc and settled on using diskd as it lasts by far the
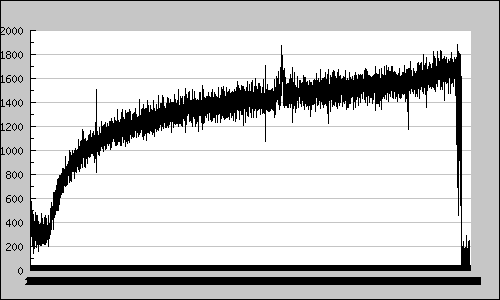
longest. I'm graphing tps (transactions per second) on the drives and there
is no plateau but a steady rise.
Right now the best configuration I have (from my tests) is 2xLSI MegaRaid
SCSI U320-1 controllers, with 4 Seagate Cheetah 15K.5 drives on each of
them. In this configuration it lasts longer than the SATA controller, but
exhibits the exact same behavior.
With 800RPS my CPU usage never goes over 50%. When I start the cache my TPS
across all the drives starts at about 400, and remains there for a few
minutes - 10->20 probably. After that it begins a steep climb, which later
flattens out a bit. This is the pattern seen in all of my tests (only the
time and total tps differ).
From my reading it would appear that the original steep climb is because
buffers become full - I wonder why it wouldn't write to the drives at full
speed to start with if needed, but this part I understand I guess. The
confusing part is why after that does it slowly and steadily rise - forever.
For example, my 800RPS test runs for 240 minutes (graph of the TPS is
attached to email), until it reaches the max tps the controller/drives seem
to be able to handle, and fails. If I do it at 600RPS it lasts 350 minutes,
also climbing though until it fails. At 1200 RPS it fails after 30 minutes.
What is causing it to constantly climb - surely if it was a queue or build
up of some type it's not reasonable to assume it might take > 300 minutes to
actually break ? If that was the case it obviously has more steam in the
first 100 minutes so why not utilize it?
I have graphs available for all the tests, and I can arrange any
stats/figures/configs etc needed - even access. I have run it at 1200 RPS
for 18 hours with a null cache directory and it did not fail, so it's
definitely disk drive handling (I guess) - but 350 minutes before it
actually fails, and a slow, steady, predictable pattern? If it was
plateau'ing like originally suggested I'd agree it's obviously hitting a
limit - but my "rawio" tests show each drive is capable of 450 random
writes/reads per second which is far higher than its doing.
Thanks
Dave
-----Original Message-----
From: Adrian Chadd [mailto:adrian@creative.net.au]
Sent: Saturday, November 10, 2007 12:13 AM
To: Dave Raven
Cc: 'Adrian Chadd'; squid-users@squid-cache.org
Subject: Re: [squid-users] Squid Performance (with Polygraph)
On Fri, Nov 09, 2007, Dave Raven wrote:
> Hi Adrian,
>
> It works for the full 4 hours with a null cache directory. How would
> I see any kind of stats/information on disk IO? From the stats I can see
so
> far, the disk stats don't change at all when it fails ...
That'd be because you're probably maxing the disk system out early on and
what you're seeing is a slowly-growing disk service queue?
> I'm currently using COSS, but I've also tried this with ufs and diskd
(with
> the same results, just different times that it fails after).
COSS should handle small object loads better but some have reported little
benefit beyond a pair of COSS disks.
Try graphing the aggregate disk and per-disk transactions/second; I bet
you'll find it plateau'ing relatively quickly early on.
Adrian
-- - Xenion - http://www.xenion.com.au/ - VPS Hosting - Commercial Squid Support - - $25/pm entry-level VPSes w/ capped bandwidth charges available in WA -